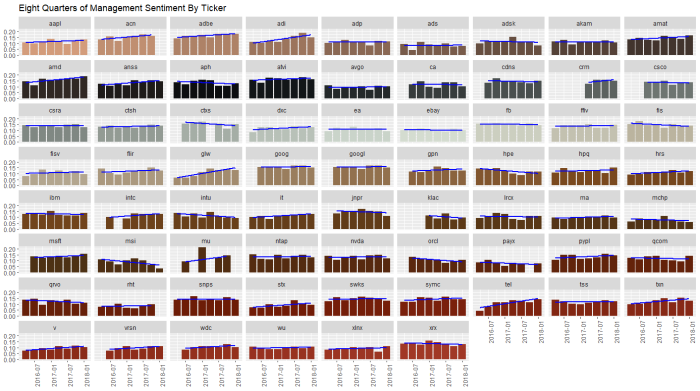
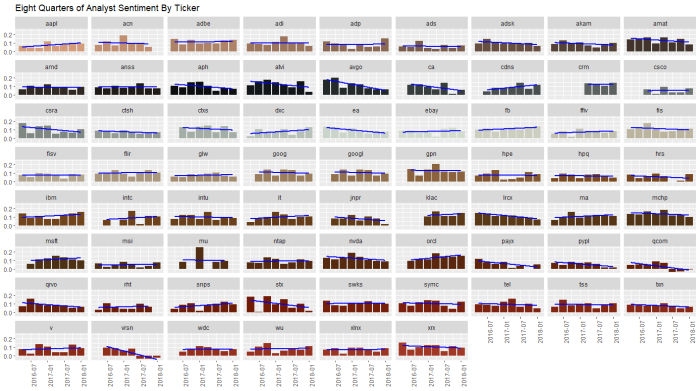
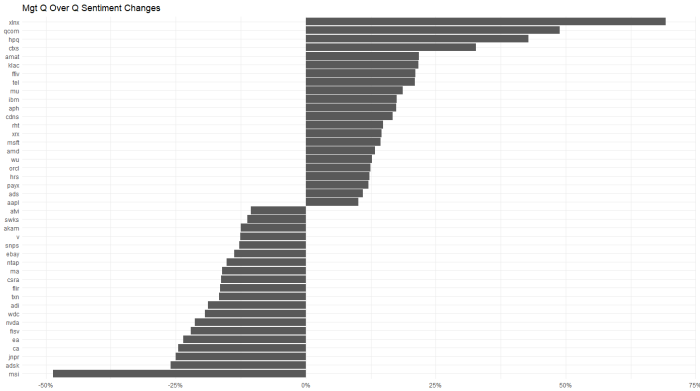
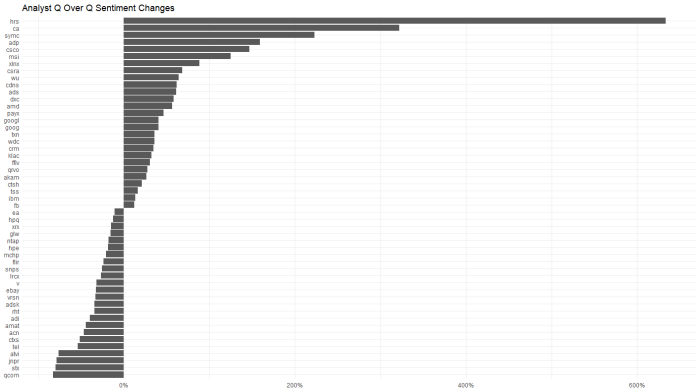
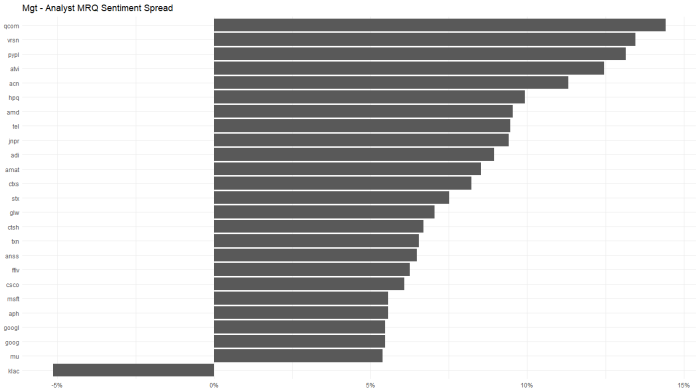
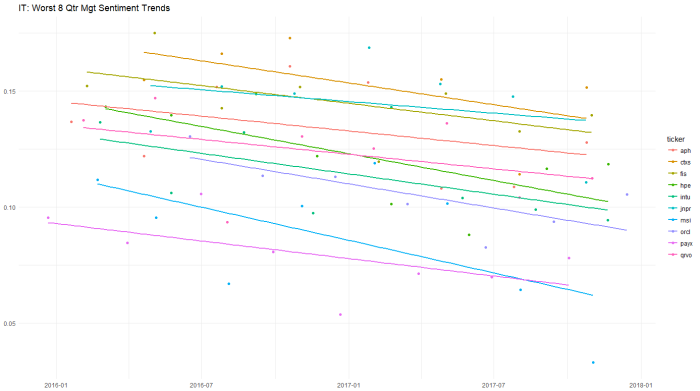
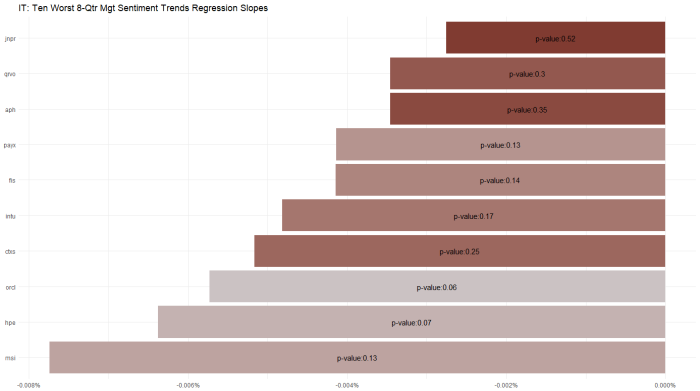
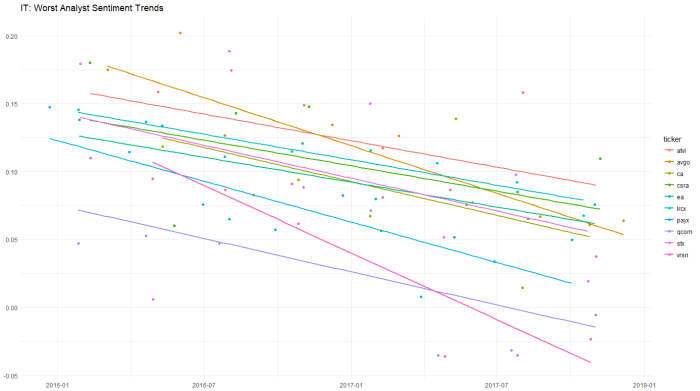
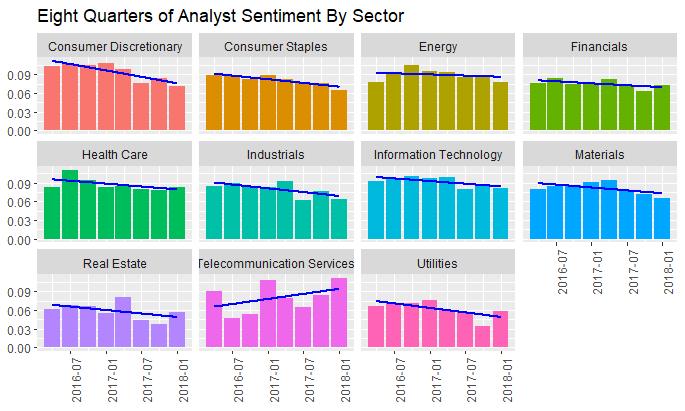
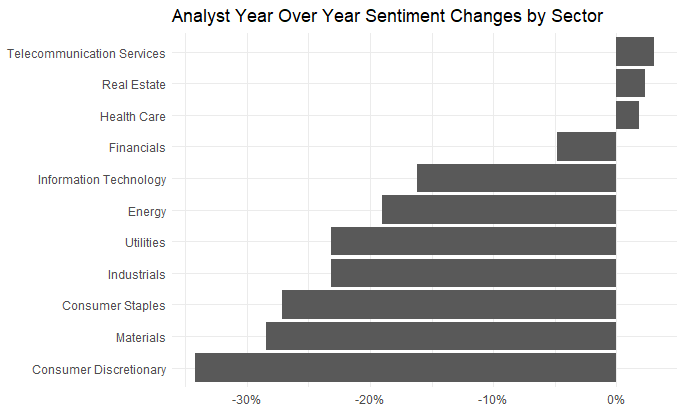
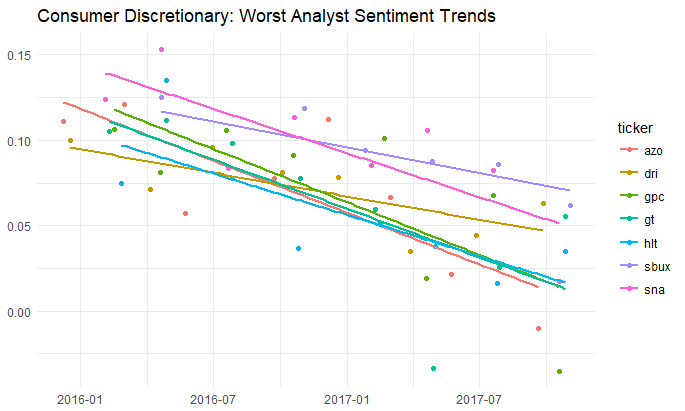
Another in a series of examples of R at work, this is a simple sector analysis of the energy sector in the S&P 500 using R and one of my favorite libraries: Tidyquant from the engineers at Business Science. Check out their site – they have a bunch of great examples on how to use R in business.
I’ve been remiss of late including code, but I’ve added much of it to the bottom of this post in this case. I’m happy to engage in discussion or debate with anyone else who has a passion for investing with data science tools. I can be found on Linkedin, for now. My github is coming soon.
Correlations? Just the First Step
The following is the 30 day rolling correlation of the 34 stocks in the Energy sector with the S&P 500.
While the correlation fell through the year as oil prices declined and tech stocks rallied, the sector has shown increasing market correlation of late.
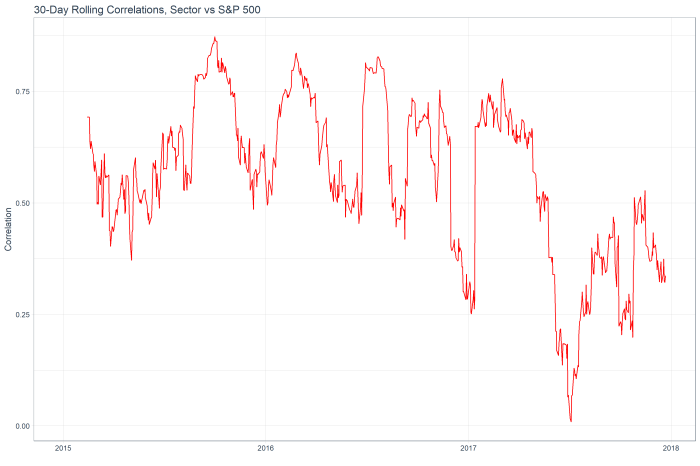
The following chart shows the top 12 stocks by correlation with the overall sector (red line) and their rolling correlation trend. With this analysis alone, I don’t see much in the way of interesting ideas. Everything appears to have mean-reverted already!
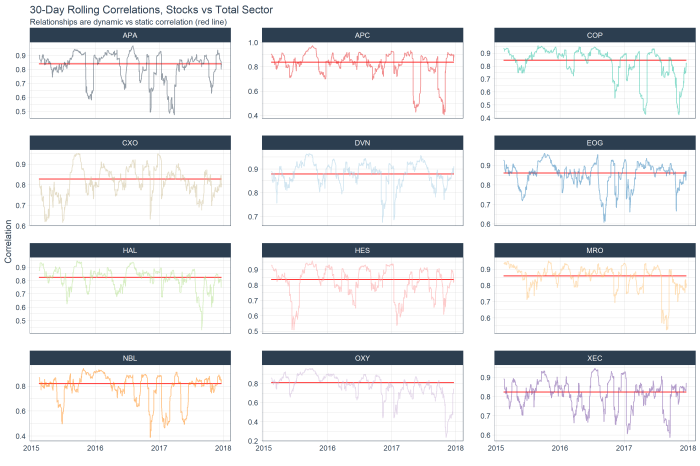
However, we can dig deeper into the idea of relationships between stocks / sector by moving past correlations and into z-scores and regression model fits.
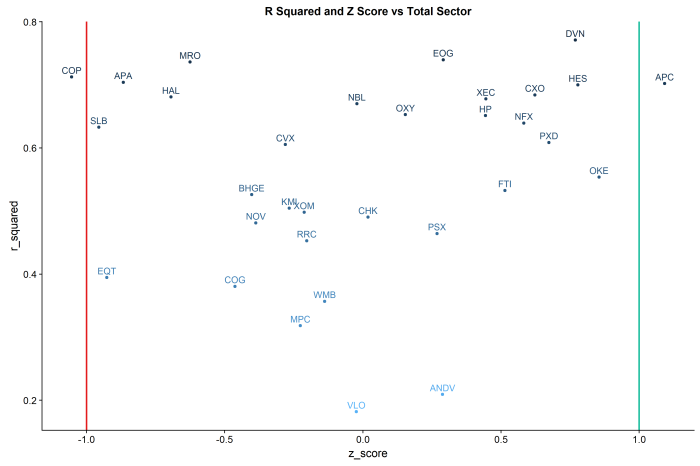
R Squared vs Z Score by Stock and Total Sector:
R Squared: The “goodness of fit”” of a linear regression of daily log returns by each stock against the total sector.
Z-Score: the measure of the current standard deviation of the daily spread of each stock’s return against that of the total sector.
Put the two ideas together, and you have a trading dashboard for the sector.
The lines in the chart are at the -1 and +1 standard deviations.
In this example, COP shows an r-squared of ~.75 and greater than -1 standard deviation from the mean of the sector, suggesting a mean reversion long. By contrast, APC shows an r-squared of ~.75 and a z-score of > 1, suggesting a mean reversion short vs the sector.
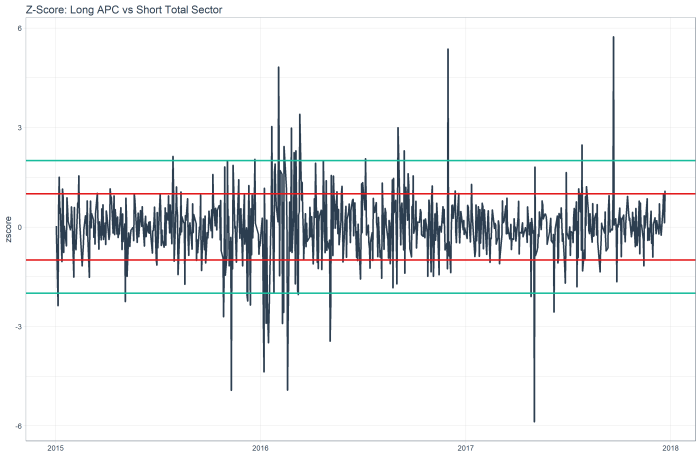
The z score chart for APC shows a mean reversion relative short, as the red line is 1 standard deviation out, and you can see this stock tends to mean revert.
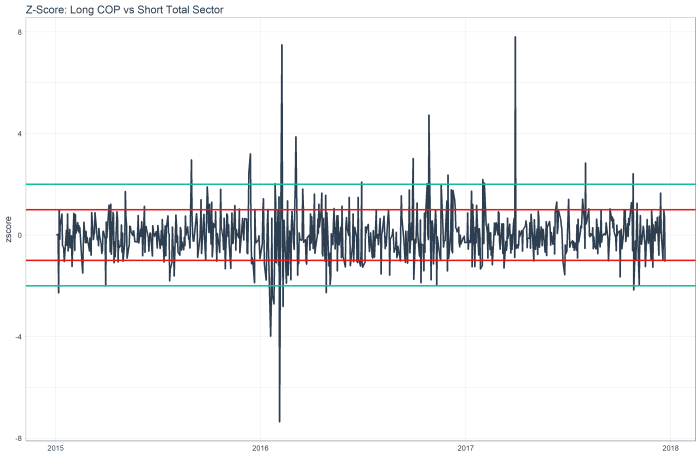
While the z score chart for COP shows a mean reversion relative long.
Code below. Ping me with any questions / ideas at jed at sentieo.com!
library(tidyquant)
sp500_stocks <- tq_index(“SP500″) #load sp500 stock symbols
stocks<-sp500_stocks %>%
filter(sector==”Energy”) #filter only the energy sector
#get prices
stock_prices <- stocks %>%
tq_get(get = “stock.prices”,
from = “2015-01-01”,
to = “2017-12-25”) %>%
group_by(symbol)
sp500_prices <- c(“^GSPC”) %>%
tq_get(get = “stock.prices”,
from = “2015-01-01”,
to = “2017-12-25”)
#calculate daily log returns
stock_pairs <- stock_prices %>%
tq_transmute(select = adjusted,
mutate_fun = periodReturn,
period = “daily”,
type = “log”,
col_rename = “returns”) %>%
group_by(date) %>%
mutate(average_sector=mean(returns)) %>%
ungroup() %>%
spread(key = symbol, value = returns)
#calculate daily log returns
sp500_returns <- sp500_prices %>%
tq_transmute(select = adjusted,
mutate_fun = periodReturn,
period = “daily”,
type = “log”,
col_rename = “returns”)
stock_returns_long<-stock_pairs %>%
gather(symbol,daily_return,-date,-average_sector)
#add rolling corr vs s&p
top_symbol<-stock_returns_long %>%
group_by(symbol) %>%
summarise(n=n()) %>%
head(1)
sp500_rolling_corr<-stock_returns_long %>%
filter(symbol==as.character(top_symbol[[1,1]])) %>%
select(date,average_sector) %>%
inner_join(sp500_returns,by=”date”) %>%
mutate(sp500_return=returns) %>%
tq_mutate_xy(
x = sp500_return,
y = average_sector,
mutate_fun = runCor,
# runCor args
n =30,
use = “pairwise.complete.obs”,
# tq_mutate args
col_rename = “rolling_corr”
)
stocks_rolling_corr<-NULL
stocks_rolling_corr <- stock_returns_long %>%
na.omit() %>%
group_by(symbol) %>%
# Mutation
tq_mutate_xy(
x = daily_return,
y = average_sector,
mutate_fun = runCor,
# runCor args
n =30,
use = “pairwise.complete.obs”,
# tq_mutate args
col_rename = “rolling_corr”
)
####GENERIC MODEL FIT
r_squareds<-stock_returns_long %>%
nest(-symbol) %>%
mutate(model=purrr::map(data,~lm(daily_return~average_sector,data=.))) %>%
unnest(model %>% purrr::map(broom::glance)) %>%
select(symbol,r.squared)
z_score<-function(data) {
data<-data %>%
mutate(z_score=(diff_series-mean(data$diff_series))/sd(data$diff_series)) %>%
select(date,z_score)
return(data)
}
current_z_scores<-stock_returns_long %>%
mutate(diff_series=daily_return-average_sector) %>%
nest(-symbol) %>%
mutate(zscore=purrr::map(data,z_score)) %>%
unnest(zscore) %>%
filter(date==max(date)) %>%
arrange(z_score)
#PLOT RSQ and ZSCORE
gplot_rsq_z<-inner_join(r_squareds,current_z_scores,by=”symbol”) %>%
mutate(r_squared=r.squared) %>%
ggplot(aes(y=r_squared,x=z_score,colour=-r.squared)) +
geom_point() +
geom_text(aes(label=symbol),size=4,vjust=-.5) +
geom_vline(xintercept = -1, size = 1, color = palette_light()[[2]]) +
geom_vline(xintercept = 1, size = 1, color = palette_light()[[3]]) +
labs(title=”R Squared and Z Score vs Total Sector”) +
theme(legend.position=”none”)